Fluent-Bit & the power-ragers-esque superbug
I’ve been investigating an issue with some missing logs on some of my Kubernetes clusters, and found three independent bugs that come together to form a
super-bug
WARNING
I’m just an Ops guy - I have little-to-no experience with C, but I can read most languages. Just letting you know that information here might be incorrect, or just… ‘misguided’.
the problem
I noticed that I was getting lots of fluent-bit pod restarts on some of my clusters, but the data looked… weird.
Essentially the pod would start dropping logs, whilst complaining about the buffer being full, and then a short while later the liveness probes indicated it was FUBAR and would restart the container… just to end up back where it started not long after. But looking at the memory usage on the pod, it seemed that when it was dropping logs complaining about the buffer being full, the memory was lower than normal usage.
So, to summarise the strangeness:
Memory goes down,
Pod logs complaining about the buffer being full,
Logs dropping at a rate of 20=>100%, starting low and increasing over time,
When they are dropping essentially everything, k8s restarts the container.
I would like to say at this point that this bug/these bugs took me 4 × 12 hour days to find answers to, one of which was a weekend. This wasn’t something I just stumbled into — it took absolutely ages to find the real root cause, even though the thing that triggered it was something fairly trivial (more on this later).
A buffer packed to the gills
As always, I start with the logs to see what the pod thinks is the matter. I know that Kubernetes has decided that it should kill the pod because of liveness probes, but the logs just keep banging on about:
Buffer is full: current_buffer_size=499997739, new_data=20752, store_dir_limit_size=500000000 bytes
Could not buffer chunk. Data order preservation will be compromised
chunk 'chunk_id' cannot be retried: task_id=<id>, input=<input> > output=s3Right up until liveness probes die, and then I get:
caught signal (SIGTERM)Beyond the SIGTERM, it’s just things shutting down, threads closing, the odd retry failing or whatever, but it’s basically shutting up shop, which is expected.
Bug one: retry_limit
Looking further back at the logs, it seems as though there may have been the odd transient failure talking to s3. This is sort of by-the-by, but transient failures, at least in my mind, are… expected? If the system or application can’t handle the odd bit of unavailability due to some network instability, it’s built wrong.
I don’t know if you’ve ever come across them, but there’s a list of “distributed system fallacies”. One of those fallacies is “The network is 100% reliable”. That is to say that these kinds of transient failures should not only be completely expected, but the application should be able to handle them. Instead, what I see is this:
[error] [output:s3:s3] PutObject request failed
[ warn] [output:s3:s3] Chunk file failed to send 1 times, will not retryBut wait. Don’t the docs for this particular version out right say that the retry limit is 5? Oh yes… so they do:
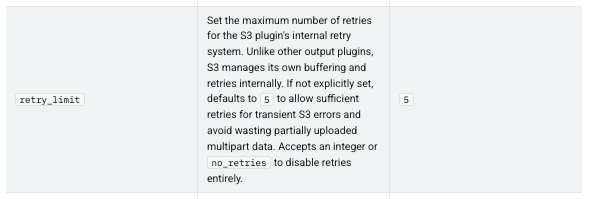
So, you can imagine my befuddlement with this. However after having a quick look at the source, it turns out that this particular version does not have a default of 5 after all, and it is in fact… 1:
# ...
instance->retry_limit = 1;
#...An unset retry_limit defaults to 1
Bug two: Off-by-One
Now we know that:
The retry limit is not 5; but is, in fact, 1, ← Bug #1
S3 is failing to upload,
the ‘buffer’ is filling up (whatever the ‘buffer’ is, it’s clearly not a memory buffer).
Now what if I told you the retry limit is not 1, but is actually… zero?
Fluent-bit’s S3 output — at least in this version, and some later versions — has some retry logic, which states the following:
ret = s3_put_object( #... )
#...
if (ret < 0) { #<-- "if s3_put_object failed"
s3_store_file_unlock(chunk);
chunk->failures += 1;
return -1;
}and
upload_contents->retry_counter++;
if (upload_contents->retry_counter >= ctx->ins->retry_limit) {
flb_plg_warn(ctx->ins, "Chunk file failed to send %d times, will not "
"retry", upload_contents->retry_counter);
s3_store_file_inactive(ctx, upload_contents->upload_file);
#...
}Now, the estute amongst you will notice a slight issue here. When it fails on putting the object into S3, it does failures += 1, which is functionally identical to failures = failures + 1. But then it passes the object to our retry mechanism, and it asks “are our failures greater than or equal to the amount of times I should retry”. The answer to that is… yes.
It fails once to upload so our failures is 1. Our retry_limit is also 1. Those are the ‘equal to’ part of our conditional. As such, it doesn’t retry at all.
retry_limit has an off-by-one erroR
Bug three: the buffer
Okay, so we know the following:
The default retry_limit is not 5; but is, in fact, 1, ← Bug #1
Functionally, retry_limit is not 1; but is, in fact, 0, ← Bug #2
S3 is failing to upload,
Whatever our ‘buffer’ is, it is continually filling up.
Whilst rummaging around in this source for fluent, I found myself looking at how the buffer actually works. As I suspected, S3 output does not store these logs in memory.
I mean, logically this makes sense — if I have bounties of logs, any slight transient failure will explode memory and the pod will get OOMKilled by the kernel/cgroup. It’ll probably be fine if there are no transient failures; but as I said before, transient failures are expected.
Anyway enough waffling… The buffer is in fact a disk resource managed by fluent itself. Whenever a log enters the buffer, it ‘manually’ increases the ‘used space’ value:
ctx->current_buffer_size += bytes;And there is a function here to delete the file, which relinquishes the buffer space back as it deletes the file.
int s3_store_file_delete(struct flb_s3 *ctx, struct s3_file *s3_file)
{
# ...
ctx->current_buffer_size -= s3_file->size;
# ...
}Top banana… Right?

Our “retry limit exceeded” error does not call s3_store_file_delete. As you can see from the code samples above, it in fact calls s3_store_file_inactive. There’s one key difference between these two functions:
s3_store_file_inactive does not free up buffer space. It just ‘forgets’ the file (using flb_fstore_file_inactive), and carries on as if nothing has happened. It doesn’t even know the file exists anymore, but continue to hold that buffer space as ‘in-use’.
And as such…
failed uploads are dropped, buffer space is not
the Super-Bug
So now I have indentified three completely independent bugs (in this version):
retry_limit defaults to 1, not 5,
A retry limit of 1 effectively means “do not retry”,
If a file fails to retry, it is forgotten about, but the on-disk buffer space is never relinquished back to the application.
All three of these would be relatively fine in isolation, but all together in the same version? Well…

There’s a reason I called this a Power-Rangers-Esque Superbug… Simply put, when all three of these exist on the same system at the same time, it spells havoc. If you have enough transient failures, fluent-bit will eventually fill it’s buffer full of files it no longer even know about. The buffer will progressively get more and more packed with smaller files all whilst it’s rejecting most of your other larger logs.
At least, until livenessProbes fail and it’ll restart.
How to fix it
Given that these three bugs only really become majorly problematic if they all coexist at the same time… what if I just, ya know, turned one off? I have at least one lever I can pull to functionally turn off two of these bugs simultaneously:
retry_limit: 6Yes, it’s that simple — Manually set the retry_limit to 6, and this means that the off-by-one causes you have the expected number of retries (i.e. five), and transient failures are, once again, smoothed over by retries.
I’m sorry if that was anti-climactic for you.
Addendum
The fluent-bit chaps picked up that issue fairly quickly, as the issue did exist in the latest version (I checked). They have since submitted and merged a PR that allows the operators to select what they would like to happen when a file fails to upload: Permanently Delete, or ‘Forget’.
Big props to the fluent-bit chaps for the speed at which they fixed it and got it released. It’s been a while since I submitted an issue for a repo and got even a reply within 6 months. Refreshing.
Nice work, chaps 👏